Overview
In the field of video generation, the latest and best-performing Video Diffusion Transformer models all
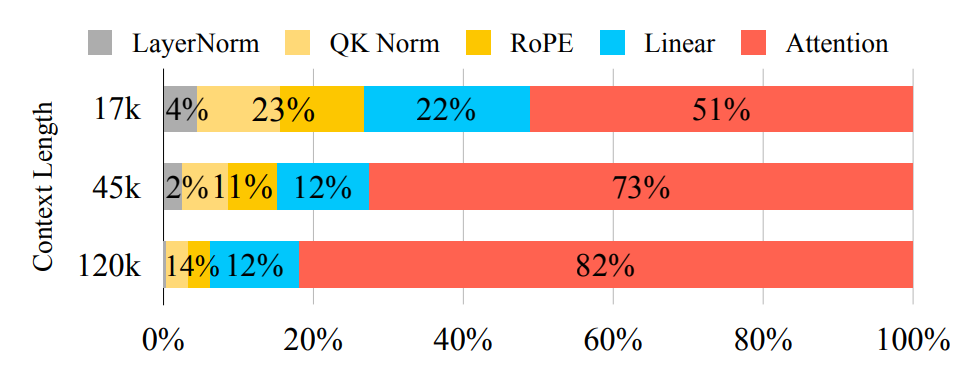
employ 3D Full Attention. However, their substantial computational demands pose significant challenges for
real-world applications. For example, HunyuanVideo takes 30 minutes to generate a 5-second video on
1×H100, which is prohibitively time-consuming due to the O(n^2) computation of 3D Full Attention.
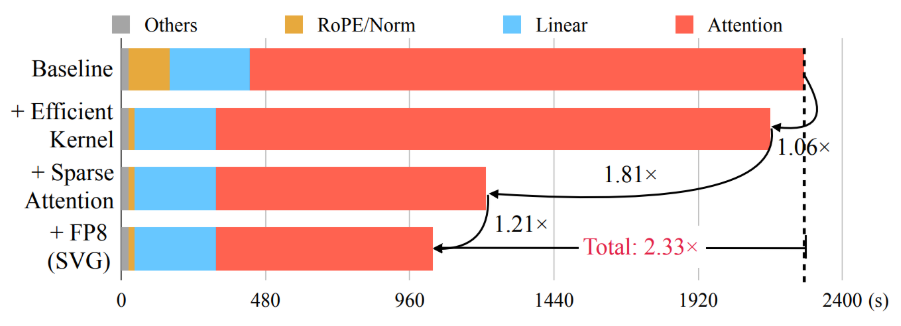
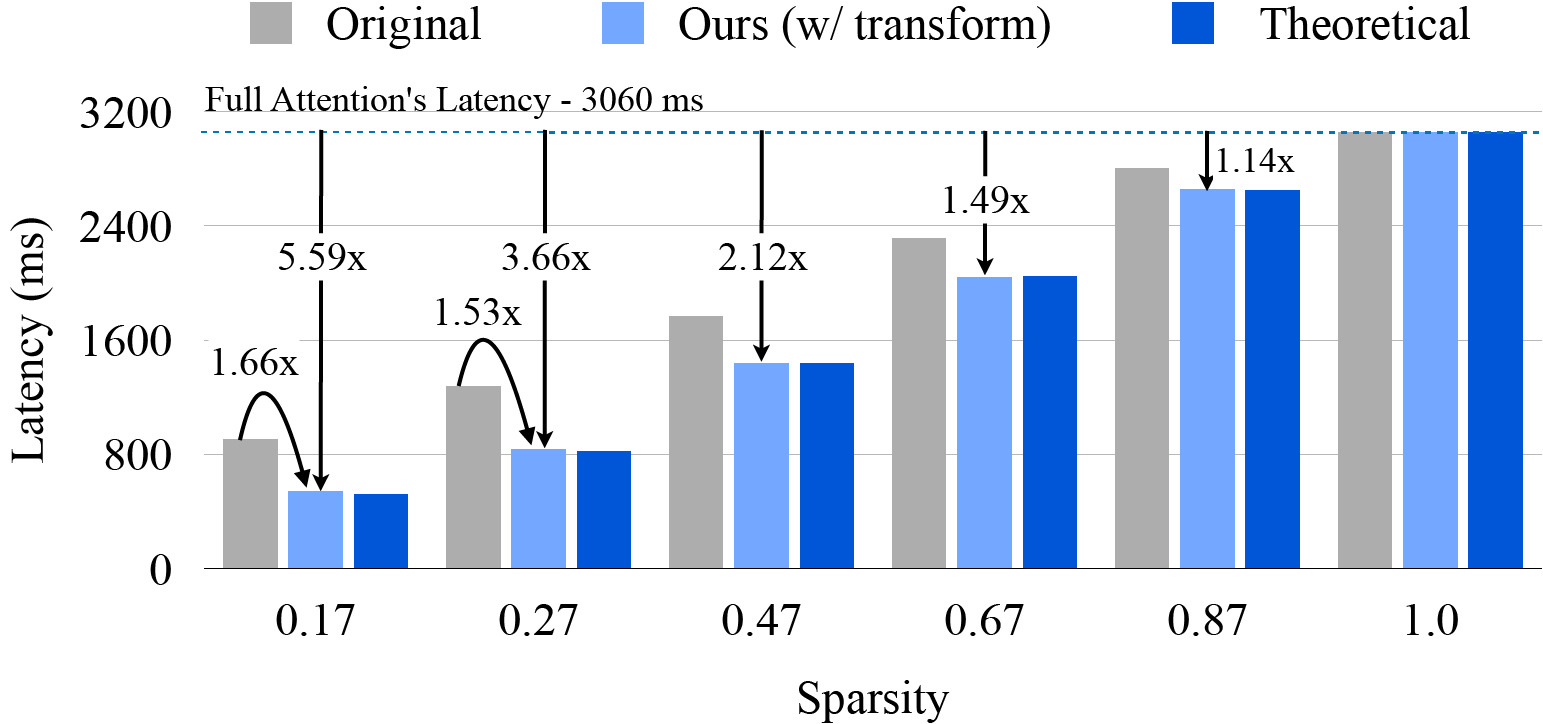
To speed up their inference, we introduce Sparse VideoGen (SVG), a training-free
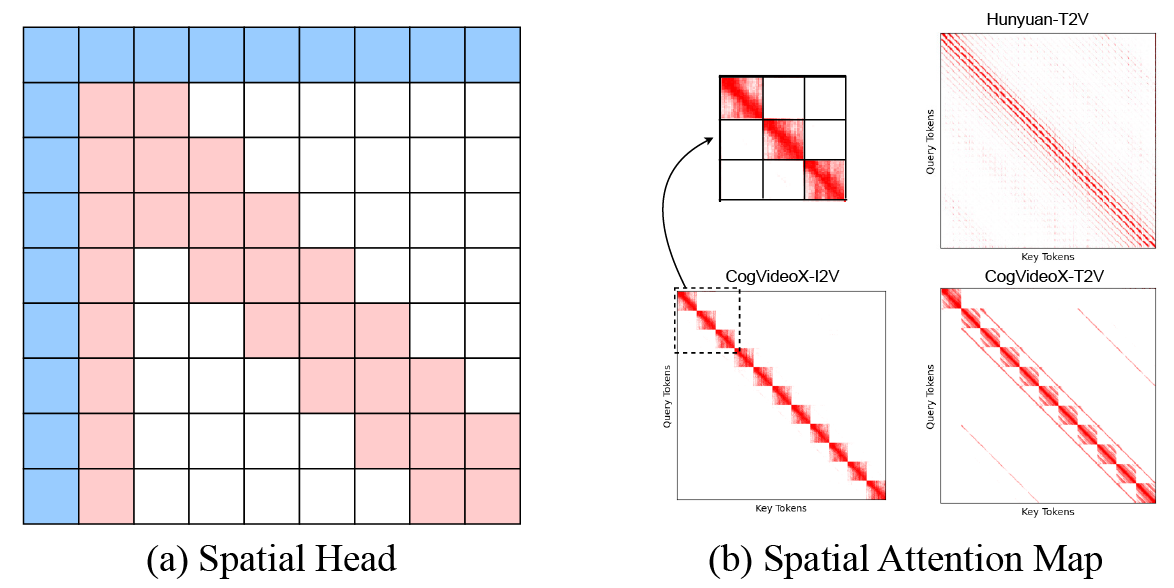
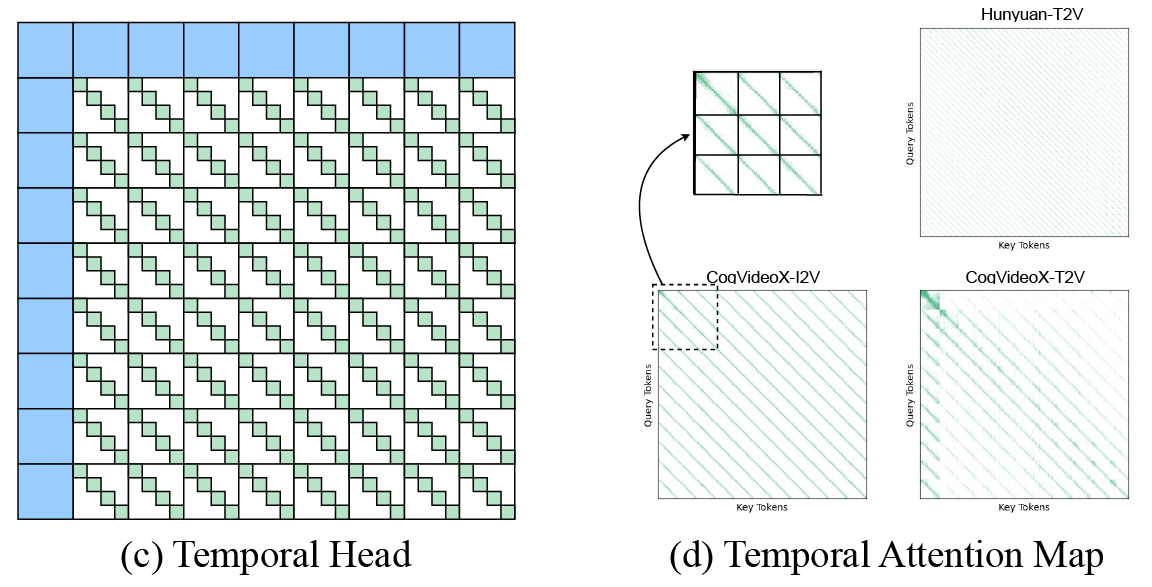
framework that leverages inherent spatial and temporal sparsity in the 3D Full Attention
operations. Sparse VideoGen's core contributions include
- Identifying the spatial and temporal sparsity patterns in video diffusion models.
- Proposing an Online Profiling Strategy to dynamically identify these patterns.
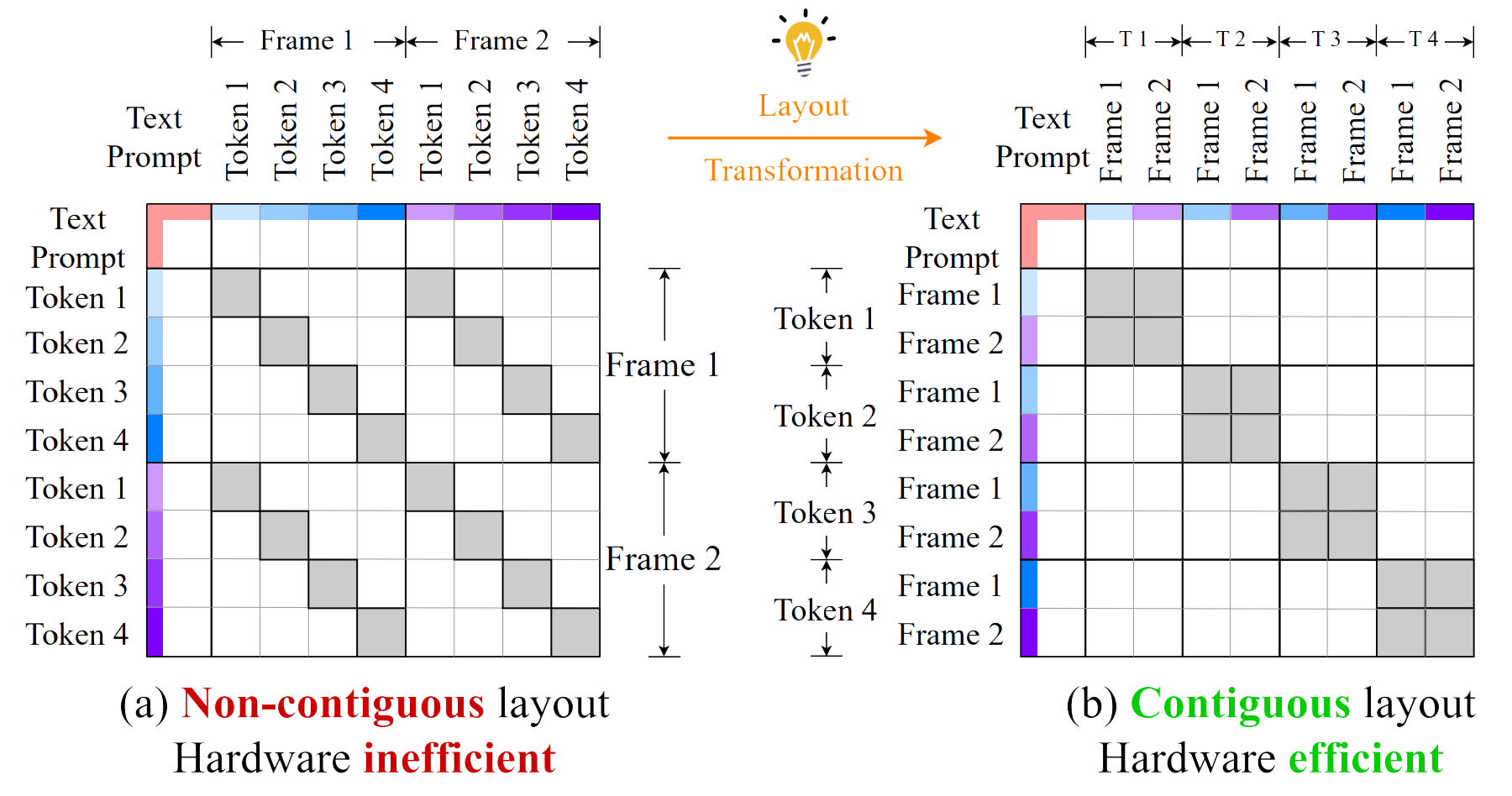
- Implementing an end-to-end generation framework through efficient algorithm-system co-design, with hardware-efficient layout transformation and customized kernels