Overview
Auto-regressive video diffusion marks a paradigm shift in video generation: by enforcing temporal causality, models like LongCat-Video, HY-WorldPlay, and Self-Forcing can generate long, streaming videos incrementally. This enables applications ranging from live-streaming generation to interactive world models.
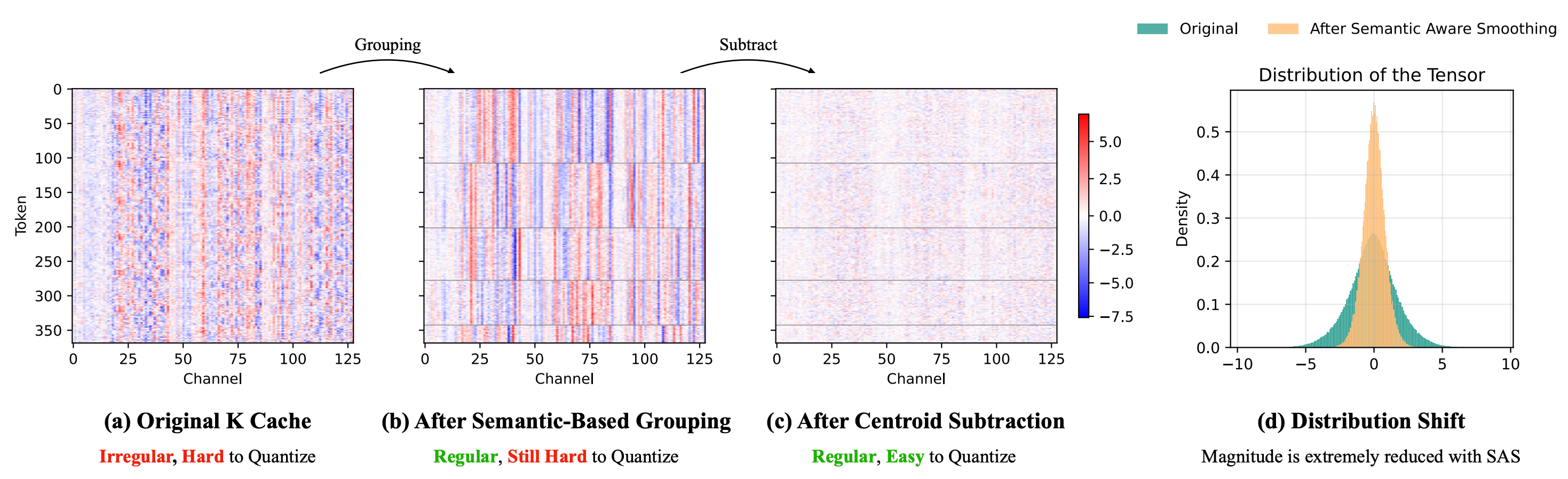
However, auto-regressive inference introduces a critical system and algorithm coupled bottleneck: KV-cache memory. Unlike bidirectional models, auto-regressive models must retain a growing KV-cache to condition on all previously generated frames. This cache grows linearly with history and quickly dominates GPU memory.
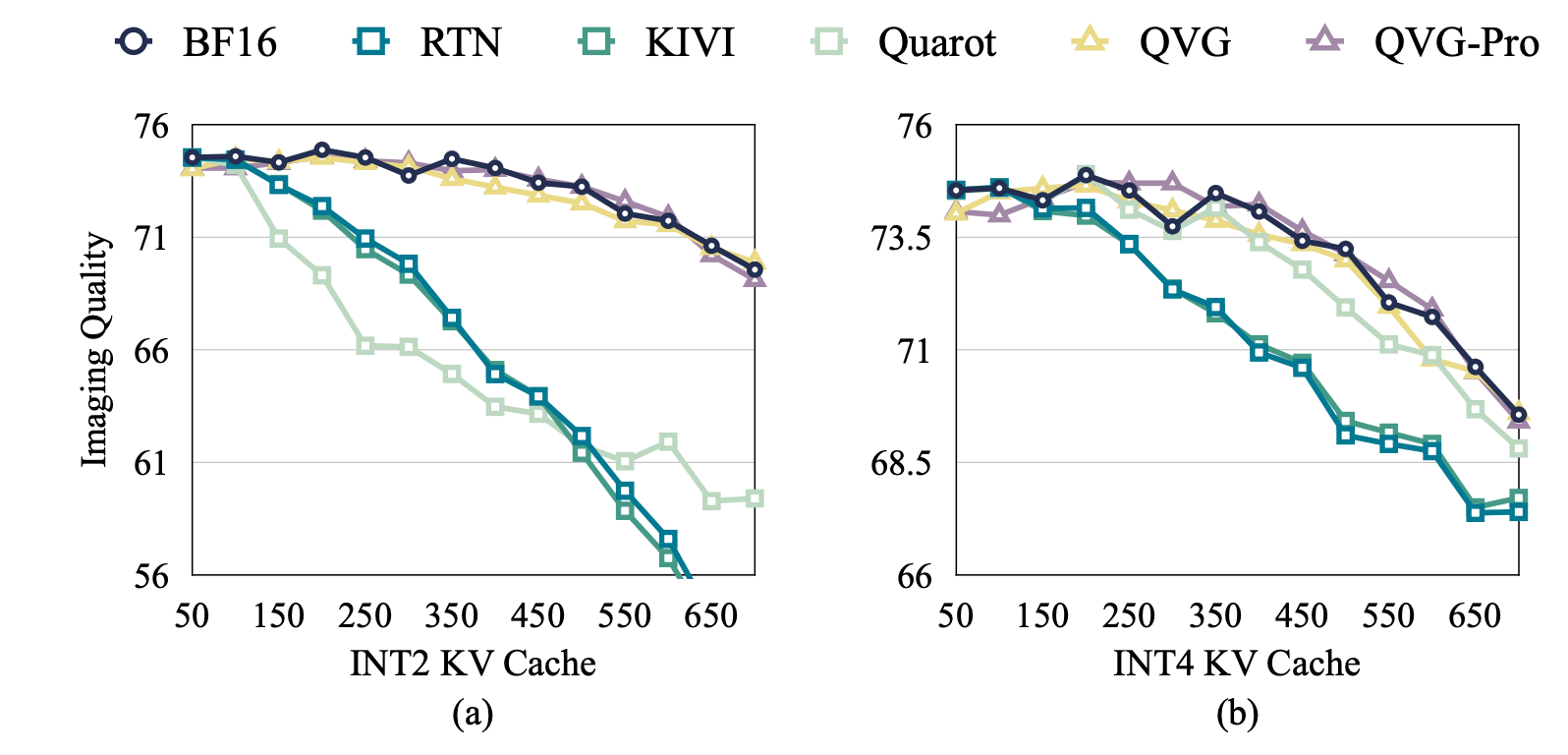
More critically, KV-cache is not just an efficiency bottleneck. It is also a capability bottleneck. When memory forces a truncated context window, the model's effective working memory shrinks, directly degrading long-horizon consistency in identity, layout, and motion. Retaining more history leads to substantially better generation quality.
QVG bridges this gap through the following approaches:
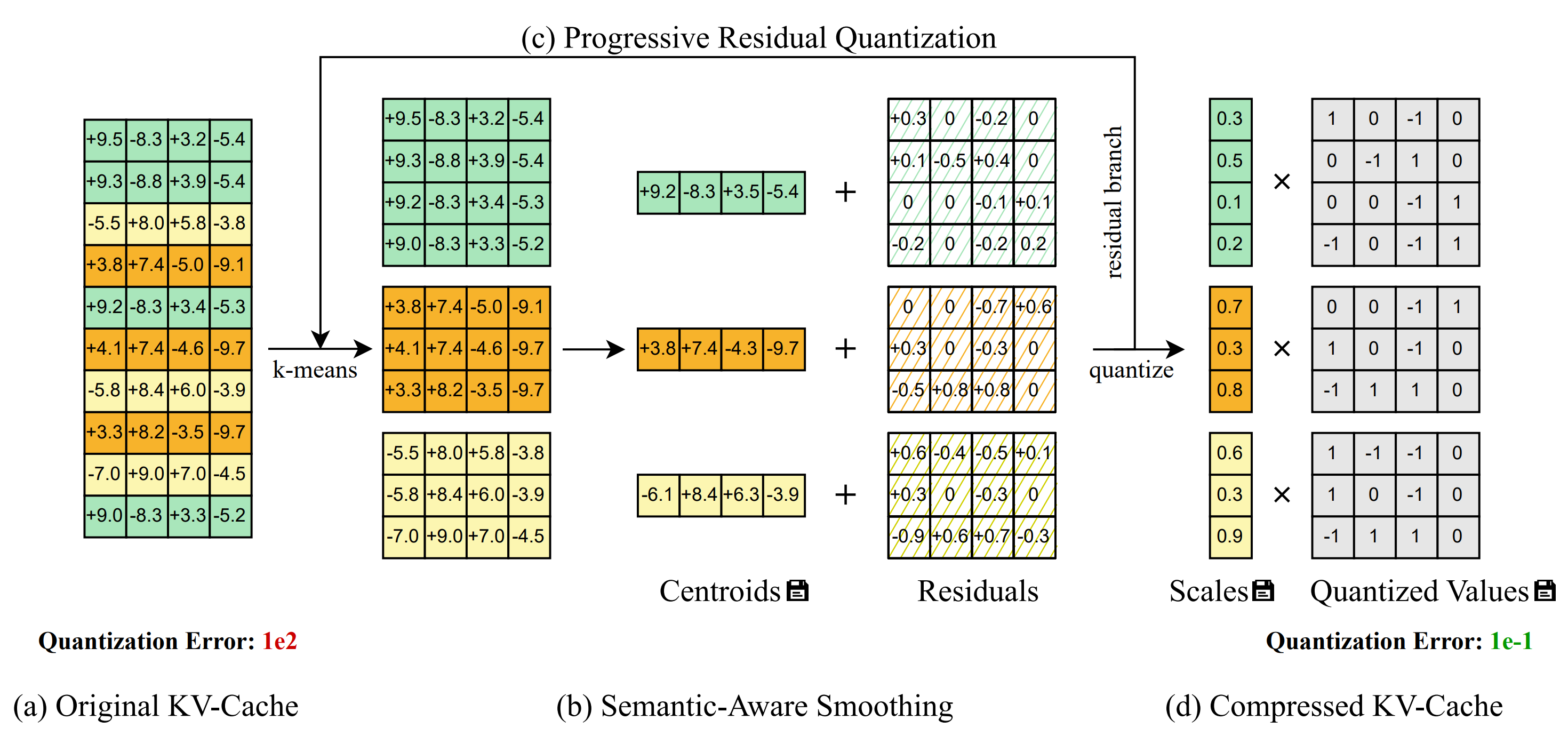
- Semantic-Aware Smoothing exploits spatiotemporal redundancy to produce quantization-friendly residuals.
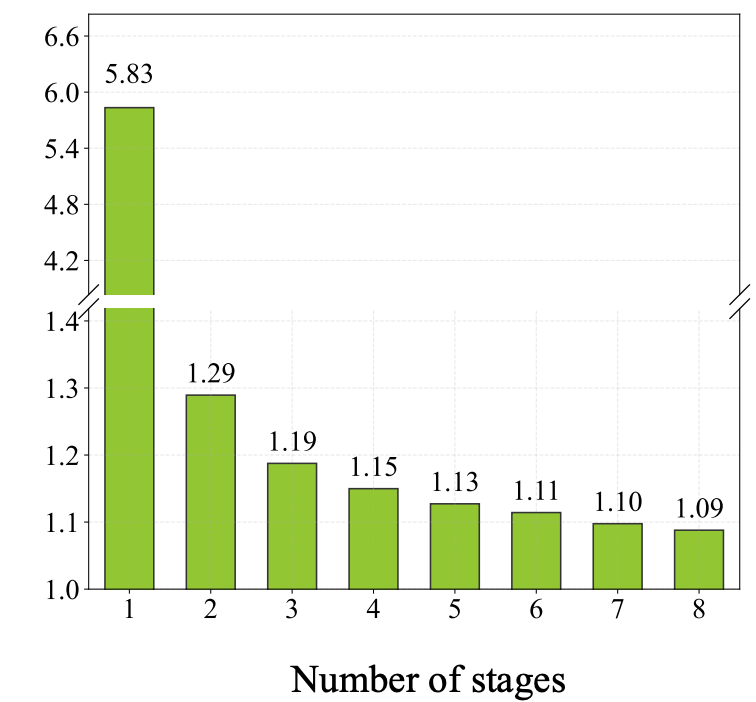
- Progressive Residual Quantization is a coarse-to-fine multi-stage scheme that further reduces quantization error.
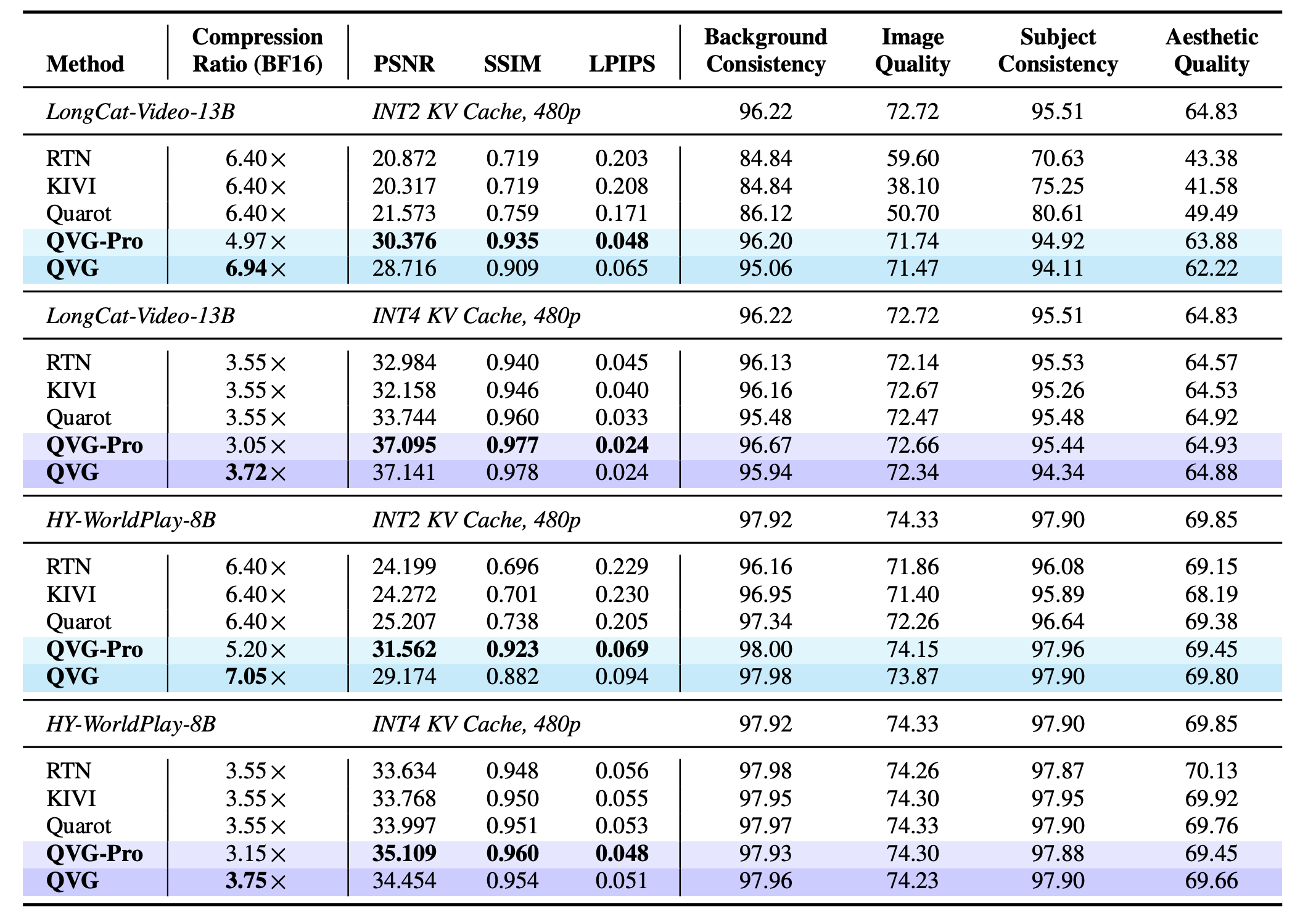
QVG reduces KV-cache memory by up to about 7× compared to BF16 while adding less than 4% end-to-end latency overhead. It also improves quantization error substantially relative to prior KV-cache quantization baselines at similar compression.